Capítulo 5
3-Modelo Lógico - Modelo Relacional
Modelo Lógico - Introdução
Introdução
Nessa seção vamos estudar o mapeamento do modelo ER para o modelo lógico (que no nosso caso será o modelo relacional).
Atenção!
Existem outras formas de fazermos o modelamento conceitual e de fazermos o modelo lógico. Veja as figuas dadas a seguir.

Figura 1: Diferentes Modelos Lógicos
Exemplos de Modelagens Conceitual->Lógica
Nas figuras 2 a 5 são apresentadas configurações possíveis para a modelagem Conceitual e Lógica.
(Figuras extraídas das aulas do professor André Santanchè, Unicamp. Clique aqui para ver o vídeo da aula de "Mapeamento Conceitual-Lógico")
(Veja também o slide sobre mapeamento modelo conceitual-lógico do Prof. André nesse link.)

Figura 2: Mapeamentodo modelo conceitual na abordagem ER para modelo lógico Relacional.

Figura 3: Mapeamento modelo conceitual na abordagem ER para modelo lógico de Objetos.

Figura 4: Mapeamento modelo conceitual na abordagem de objetos para modelo lógico Relacional.
Figura 5: Mapeamento modelo na abordagem Objetos para modelo lógico de Objetos.
Abordagem ER e Relacional
A abordagem ER vista na seção anterior, é voltada à modelagem de dados de forma independente do SGBD considerado. É adequada para construção do modelo conceitual.
Já a abordagem relacional modela os dados a nível de SGBD relacional. Um modelo neste nível de abstração é chamado de modelo lógico.
O modelo lógico consiste na especificcao lógica (logicamente...) da estrutura do banco de dados. Ele já aproxima o modelo conceitual da realidade da implementação no SCBD.
Por exemplo, nesse momento os tipos de dados devem ser detalhados e as relações devem ser explicitadas.
Nesse nível da modelagem, já fazemos a modelagem pensando no SGBD que será usado.
Lembre-se que o banco relacional, usando tabelas, é UMA OPÇÃO. Mas podemos ter outros tipos de modelos lógicos, associados a outros tipos de banco de dados, como por exemplo o modelo lógico hierárquico (que usa estrutura de árvores e faz uso por exemplo das linguagens JSON/XML) ou o modelo de grafos.
(A figura 1 acima apresenta alguns modelos lógicos de banco de dados).Modelo Lógico - Conceitos
Vamos estudar o projeto lógico de BD relacional.
Como dito, abordaremos o mapeamento do modelo conceitual construído na abordagem ER para o modelo lógico relacional, que implementa, a nível de SGBD relacional, os dados representados abstratamente no modelo ER.
O termo "implementação" significa que ocorre uma transformação de um modelo mais abstrato para um modelo que contém mais detalhes de implementação.
Um determinado modelo ER pode ser implementado através de diversos modelos relacionais, que contém as informações especificadas pelo diagrama ER. Todos podem ser considerados uma implementação correta do modelo ER considerado.
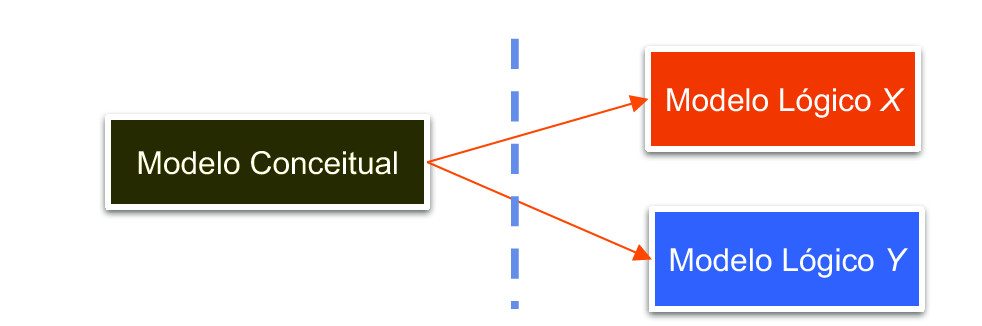
Figura 6: Um modelo conceitual pode derivar diferentes modelos lógicos
Entretanto, estes diferentes modelos relacionais podem resultar em diferentes performances do sistema construído sobre o banco de dados e podem implicar maior facilidade, ou dificuldade de desenvolvimento e manutenção do sistema construído sobre o banco de dados.
Geralmente fazemos um modelo lógico inicial e caso esse modelo não atenda aos requisitos de performance da BD projetada, há um processo de refinamento e melhoria do modelo, até ser atingido o modelo relacional satisfatório.

Figura 7: Processo de criação do modelo Lógico
Revendo os Conceitos do Banco Relacional
Principais Conceitos
Um banco de dados relacional é composto de tabelas ou relações.
A terminologia tabela é mais comum nos produtos comerciais e na prática.
Já a terminologia relação foi utilizada na literatura original sobre a abordagem relacional (daí a denominação “relacional”) e é mais comum na área acadêmica e nos livros texto.
Tabela
Uma tabela é um conjunto não ordenado de linhas (tuplas, na terminologia acadêmica).
Cada linha é composta por uma série de campos (valor de atributo, na terminologia acadêmica).
Cada campo é identificado por nome de campo (nome de atributo, na terminologia acadêmica).
O conjunto de campos das linhas de uma tabela que possuem o mesmo nome formam uma coluna.
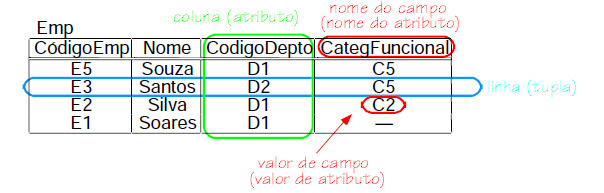
Figura 8: Conceituação (formal) de uma tabela.
Conceito de Chave
O conceito básico para estabelecer relações entre linhas de tabelas de um banco de dados relacional é o da chave.
Em um banco de dados relacional, há ao menos três tipos de chaves a considerar:
chave primária
chave estrangeira,
chave alternativa\.
Chave Primária
Uma chave primária é uma coluna ou uma combinação de colunas cujos valores distinguem uma linha das demais dentro de uma tabela.
Na tabela Emp da Figura 8 acima, a chave primária é a coluna CódigoEmp. Na figura 9 abaixo a chave primária é a coluna "identidade".

Figura 9: Exemplo de chave primária
A Figura 10 abaixo apresenta um exemplo de uma tabela (Dependente) que possui uma chave primária composta (colunas CódigoEmp e NoDepen).
Neste caso, apenas um dos valores dos campos que compõem a chave não é suficiente para distinguir uma linha das demais, já que tanto um código de empregado (CódigoEmp) pode aparecer em diferentes linhas, quanto um número de dependente (NoDepen) pode aparecer em diferentes linhas.
É necessário considerar ambos valores (CódigoEmp e NoDepen) para identificar uma linha na tabela, ou seja para identificar um dependente

Figura 10: Exemplo de chave primária composta
No exemplo da tabela da figura 10 acima, qualquer combinação de colunas que contenha as colunas CódigoEmp e NoDepen é uma chave primária.
Nas Por isso, nas definições formais de chave primária, exige-se que essa seja mínima. Uma chave é mínima quando todas suas colunas forem efetivamente necessárias para garantir o requisito de unicidade de valores da chave.
Exemplificando, alguém poderia considerar a combinação de colunas CódigoEmp, NoDepen e Tipo como sendo uma chave primária. Entretanto, se eliminarmos, desta combinação a coluna Tipo continuamos frente a uma chave primária. Portanto, a combinação de colunas CódigoEmp, NoDepen e Tipo não obedece o princípio da minimalidade e não deve ser considerada uma chave.
Chave Estrangeira
Uma chave estrangeira é uma coluna ou uma combinação de colunas, cujos valores aparecem necessariamente na chave primária de uma tabela.
A chave estrangeira é o mecanismo que permite a implementação de relacionamentos em um banco de dados relacional.

Figura 11: Exemplo de Chave Estrangeira: a coluna CodigoDepto da tabela Dept é a chave primária. A coluna CodigoDepto da tabela Emp é uma chave estrangeira em relação a chave primária da tabela Dept.
Nas colunas da Figura 11 a coluna CodigoDepto da tabela Emp é uma chave estrangeira em relação a chave primária da tabela Dept.
Isso significa que, na tabela Emp, não podem aparecer linhas que contenham um valor do campo CodigoDepto que não exista na coluna de mesmo nome da tabela Emp. A interpretação desta restrição é que todo empregado deve estar associado a um departamento.
Atenção
A palavra “estrangeira” usada para denominar este tipo de chave pode ser enganosa.
Ela pode levar a crer que a chave estrangeira sempre referencia uma chave primária de outra tabela.
Entretanto, esta restrição não existe. Uma chave primária pode referenciar a chave primária da própria tabela, como mostra a Figura 12.
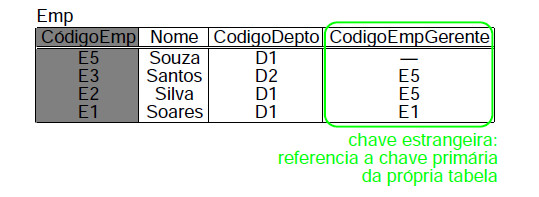
Figura 12: Exemplo de Chave Estrangeira dentro da própria tabela.
Na tabela da figura 12 a coluna CodigoEmpGerente é o código de um outro empregado, o gerente do empregado correspondente a linha em questão.
Como todo gerente é ele mesmo também um empregado, existe a restrição de que todo valor da coluna CodigoEmpGerente deve aparecer na coluna CodigoEmp.
Assim, a coluna CodigoEmpGerente é chave estrangeira em relação a chave primária da própria tabela Emp.
Chave Alternativa
Em alguns casos, mais de uma coluna ou combinações de colunas podem servir para distinguir uma linha das demais.
Uma das colunas (ou combinação de colunas) é escolhida como chave primária. As demais colunas ou combinações são denominadas chaves alternativas.

Figura 13: Chave alternativa: A coluna CIC é uma chave alternativa.
A Figura 13 mostra um exemplo de uma tabela com dados de empregados (Emp) na qual tanto a coluna CódigoEmp quanto a coluna CIC podem ser usadas para distinguir uma linha das demais. Nesta tabela, como a coluna CódigoEmp foi escolhida como chave primária, diz-se que a coluna CIC é uma chave alternativa.
Valor NULL - Domínios e Valores VAZIOS
Quando uma tabela do banco de dados é definida, para cada coluna da tabela, deve ser especificado um conjunto de valores (alfanumérico, numérico,…) que os campos da respectiva coluna podem assumir.
Este conjunto de valores é chamado de domínio da coluna ou domínio do campo.
Além disso, deve ser especificado se os campos da coluna podem estar vazios (“null” em inglês) ou não.
Estar vazio indica que o campo não recebeu nenhum valor de seu domínio.
Na Figura 13, o campo CategFuncional da linha correspondente ao empregado de código E1 está vazio.
Isso indica que o empregado E1 não possui categoria funcional ou que esta ainda não foi informada.
As colunas nas quais não são admitidos valores vazios são chamadas de colunas obrigatórias.
As colunas nas quais podem aparecer campos vazios são chamadas de colunas opcionais.
Normalmente, os SGBD relacional exigem que todas colunas que compõem a chave primária sejam obrigatórias.
A mesma exigência não é feita para as demais chaves.
Do Modelo Conceitual para o Lógico
As regras foram definidas tendo em vista dois objetivos básicos:
Obter um banco de dados que permita boa performance de instruções de consulta e alteração do banco de dados. Obter boa performance significa basicamente diminuir o número de acessos a disco, já que estes consomem o maior tempo na execução de uma instrução de banco de dados.
Obter um banco de dados que simplifique o desenvolvimento e a manutenção de aplicações.
Estes dois objetivos são os centrais. Além destes, as regras de transformação procuram obter um banco de dados que ocupe pouco espaço em disco.
O objetivo de reduzir espaço de armazenamento era até algum tempo atrás tão importante quanto o objetivo de melhorar performance e simplificar o desenvolvimento.
Entretanto, nos últimos anos, o preço dos meios de armazenamento vem diminuindo constantemente, o que fez com que a redução de espaço ocupado, principalmente se em detrimento dos demais objetivos, diminuísse de importância.
Afim de alcançar estes objetivos, as regras de tradução foram definidas tendo por base, entre outros, os seguintes princípios:
Evitar junções
Diminuir o número de chaves primárias
Evitar campos opcionais
Evitar junções
Ter os dados necessários a uma consulta em uma única linha Um SGBD relacional normalmente armazena os dados de uma linha de uma tabela contiguamente em disco.
Com isso, todos dados de uma linha são trazidos para a memória em uma operação de acesso a disco. Isso significa que, uma vez encontrada uma linha de uma tabela, seus campos estão todos disponíveis sem necessidade de acesso adicionais a disco.
Quando for necessário buscar em disco dados de diversas linhas associadas pela igualdade de campos (por exemplo, buscar os dados de um empregado e os dados de seu departamento) é necessário usar a operação de junção. Os SGBD procuram implementar a junção de forma eficiente, já que ela é uma operação executada muito freqüentemente. Mesmo assim, a junção envolve diversos acessos a disco. Assim, quando for possível, é preferível ter os dados necessários a uma consulta em uma única linha somente, ao invés de tê-los distribuídos em diversas linhas, exigindo a sua junção.
Diminuir o número de chaves primárias
Para a implementação eficiente do controle da unicidade da chave primária, o SGBD usa normalmente uma estrutura de acesso auxiliar, um índice, para cada chave primária. Índices, pela forma que são implementados, tendem a ocupar espaço considerável em disco.
Além disso, a inserção ou remoção de entradas em um índice podem exigir diversos acesso a disco. Assim sendo, quando for necessário escolher entre duas alternativas de implementação, uma na qual dados aparecem em uma única tabela e outra na qual os mesmos dados aparecem em duas ou mais tabelas com a mesma chave primária e mesmo número de linhas, a implementação por uma única tabela deve ser preferida.
Para exemplificar vamos considerar que se deseja armazenar dados sobre clientes em um banco de dados relacional. Deseja-se armazenar, para cada cliente, seu código, seu nome, o nome da pessoa de contato, o endereço e o telefone. Este dados poderiam ser implementados através de uma das seguintes alternativas:
Evitar campos opcionais
Campos opcionais são campos que podem assumir o valor VAZIO (NULL em SQL).
Os SGBD relacionais usualmente não desperdiçam espaço pelo fato de campos de uma linha estarem vazios, pois usam técnicas de compressão de dados e registros de tamanho variável no armazenamento interno de linhas.
Além disso, há uma cláusula de SQL que especifica ao SGBD se o campo deve estar preenchido ou pode estar vazio.
Assim, em princípio, não há problemas em usar este tipo de campos. Uma situação que pode gerar problemas é aquela na qual a obrigatoriedade ou não do preenchimento de um campo depende do valor de outros campos.
Neste caso, em alguns SGBD, o controle da obrigatoriedade deve ser feito pelos programas que acessam o banco de dados, o que deve ser evitado.
Etapas na Modelagem Conceitual->Lógico
Nessa seção descrevemos as ações mais comuns que temos que fazer para passar o modelo conceitual (diagrama DER) para o modelo lógico (no caso do modelo RELACIONAL, ele será construido em tabelas).
A transformação de um modelo ER em um modelo relacional dá-se nos seguintes passos:
Tradução inicial de entidades e respectivos atributos
Tradução de relacionamentos e respectivos atributos
Tradução de generalizações/especializações

Figura 14: Principais ações na conversaão Conceitual->Lógico
Comentário
Trata-se aqui de uma tradução inicial. Pelas regras que seguem nas próximas seções, as tabelas definidas nesta etapa ainda poderão ser fundidas, no caso de algumas alternativas de implementação de relacionamentos 1:1 e hierarquias de generalização/especialização.Etapa 1 - Mapeamento das Entidades
Esse passo é razoavelmente óbvio:
cada entidade é traduzida para uma tabela.
cada atributo da entidade define uma coluna da tabela.
Os atributos identificadores da entidade correspondem às colunas que compõem a chave primária da tabela.

Figura 15: Exemplo de entidade e seus atributos formando uma tabela

Figura 16: Exemplo de parte de um DER com entidade possuindo atributos derivados.
Dicas para Nome das Tabelas e Campos
Não usar espaços em branco
Não usar caracteres especiais ou acentuados
Abreviar quando possível

Figura 17: Exemplo de nomes para as colunas das tabelas.
Etapa 2 - Entidade Fraca ( Relacionamento Identificador)
Cada entidade fraca deve ser transformada em uma tabela
Incluir os atributos da chave primária da tabela dominante como chave estrangeira.
A chave primária da relação deve ser a combinação dos atributos da chave primária da relação dominante e da chave da entidade fraca.

Figura 18: Relacionamento identificador (entidade DEPENDENTE é uma "entidade fraca"). A entidade DEPEDENTE será uma tabela no modelo lógico, com relação de chaves (chave estrangeira-chave primária) com a entidade (tabela) EMPREGADO. Vide Figura 19.
No exemplo da figura 18 a entidade fraca dependente passa a ser uma tabela, com a chave estrangeria sendo composta pela chave do estrangeria da entidade empregado mais a chave primária da tabela dependente, como mostrado na Figura 19 (no formato texto).

Figura 19: Descrição das tabelas derivadas a partir do DER da Figura 18.
Regra para Mapear Entidade Fraca
-
Para cada tipo de entidade fraca F no modelo conceitual: com tipo de entidade proprietária forte F, crie uma tabela T e inclua todos os atributos simples (ou componentes simples dos atributos compostos) de F como atributos de T.
-
Além disso, inclua como atributos chave estrangeira de T os atributos de chave primária da tabela que correspondem aos de entidade proprietária E.
-
Assim mapeamos a identificação da entidade fraca F.
-
A chave primária de T é a combinação das chaves primárias da entidade proprietária E e a chave parcial do tipo de entidade fraca F, se houver
Etapa 3 - Atributos Compostos
Como dito acima, a transformação mais natural é um entidade virar tabela e seus atributos virarem colunas dessas tabelas.
Quando temos atributos compostos, podemos criar uma nova tabela e associar os dados dela a partir de chave primária-estrangeira (mais usado quando o atributo é multivalorado, ou seja, podem ter mais de um valor) ou criar os campos na mesma tabela (mais recomendado).
Nesse segundo caso, podemos, para facilitar a identificação, colocar como label do campo o nome do atrituto composto, colocando em seguida os atributos que o definem. Veja a figura 20 abaixo:

Figura 20: Exemplo de atributo composto. Pode-se criar campos na tabela fazendo referência ao atributo (e suas especificidades) ou pode-se criar uma tabela específica (menos comum) para os atributos compostos.
Etapa 4 - Atributo multivalorado
Nesse caso a recomendação é que seja criada uma tabela específica para o atributo (que poderá ter mais de um valor para cada instância da entidade). Veja a figura 21 a seguir.

Figura 21: Exemplo com atributo multi-valorado (ou seja que pode ter muitos valores para uma mesma instância.)
Comentário
Nesse caso, temos a condição de que um cliente pode ter 0 ou vários telefones. Repare que notação "pé-de-galinha" mostra do lado do cliente "apenas um" e do lado do telefone, "0 ou vários".
Cllique para rever as relações da notação James Martin (pé-de-galinha).
Etapa 5- Mapeando Relacionamentos
Existem três maneiras de se mapear os relacionamentos
Criar Tabela Própria
Indicado para cardinalidades N:N em ambos os lados.
Criar uma tabela para o relacionamento.
Inserir atributo(s) do relacionamento.
A chave primária é formada pela concatenação das chaves de todas as entidades envolvidas no relacionamento.
Colunas Adicionais
Indicado para cardinalidades 1:N e 1:1.
Incluir chave estrangeira e atributos na tabela correspondente à entidade que desempenha o papel com cardinalidade máxima n.
Fusão de Tabelas
Indicado para cardinalidades 1:1 em ambos os lados.
Substituir as duas entidades originais por uma única entidade.
Escolher uma das identificações como chave primária
Mapeamento de Relacionamento 1:1
Nos slides dados abaixo temos os exemplos de mapeamento de Entidade-Relacionamento para o caso 1:1.
Temos duas opções:
Colunas Adicionais: manter as duas tabelas das entidades 1 e 2 do relacionamento, relacionando-as a partir da relação de chaves (PK-FK).
Criar uma única tabela, com os atributos das duas entidades, escolhendo uma chave primária
Mostramos também um exmeplo com um relacionamento com atributo. Nesse caso podemos ter uma terceira tabela, que contempla o atributo do relacionamento.
Exemplo 1: Mapeamento de relacionamento 1:1
Vide o Exercício 1 sobre esses exemplos do mapeamento 1:1.
Mapeamento de Relacionamento 1:N
Nos slides dados abaixo temos os exemplos de mapeamento de Entidade-Relacionamento para o caso 1:N.
Para o caso 1:N, quando não há atributo na relação, usa-se a opção de duas tabelas, com a relação PK-FK entre elas. Geralmente o "lado N" conterá a chave estrangeria (FK) da chave primária ("lado 1").
No caso em que o relacionamento possui atributos, temos duas opções:
Colunas Adicionais: manter as duas tabelas das entidades 1 e 2 do relacionamento, relacionando-as a partir da relação de chaves (PK-FK).
Criar uma terceira tabela, que relaciona as entidades 1 e 2 do relacionamento.
Exemplo 2: Mapeamento de relacionamento 1:N
Vide o Exercício 3 sobre os esses exemplos do mapeamento 1:N.
Mapeamento de Relacionamento 1:N
Nos slides dados abaixo temos os exemplos de mapeamento de Entidade-Relacionamento para o caso 1:N.
Para o caso 1:N, quando não há atributo na relação, usa-se a opção de duas tabelas, com a relação PK-FK entre elas. Geralmente o "lado N" conterá a chave estrangeria (FK) da chave primária ("lado 1").
No caso em que o relacionamento possui atributos, temos duas opções:
Colunas Adicionais: manter as duas tabelas das entidades 1 e 2 do relacionamento, relacionando-as a partir da relação de chaves (PK-FK).
Criar uma terceira tabela, que relaciona as entidades 1 e 2 do relacionamento.
Exemplo 3: Mapeamento de relacionamento N:N
Vide o Exercício 4 sobre os esses exemplos do mapeamento 1:N.

Figura 22: Recomendações para escolha da estrutura do modelo lógico.
Exercícios
Exercício 1
Para os dois casos do mapeamento de relacionamento 1:1 dados no exemplo 1, a saber o exemplo do DER PESSOA-ENDEREÇO e PESSOA-CONTA, apresente o modelo lógico relacional para os casos não dados nos exemplos, ou seja, o caso "tabela única" no exemplo PESSOA-ENDEREÇO e o caso "tabela com relacionamento" no caso PESSOA-CONTA.
Você pode usar ferramentas online de modelagem ou (preferencialmente) o MysqlWorkbench.
Exercício 2
Crie exemplos diferentes dos dados no exercício 1 acima para relacionamentos 1:1 e 1:N. Para ambos faça:
Modelo usando DER. Para relacionamento binário com e sem atributo.
Modelo lógico a partir do DER criado.
Apresente os diagramas ER e as tabelas do modelo relacional.
Você pode usar ferramentas online de modelagem ou (preferencialmente) o MysqlWorkbench.
Exercício 3
Estude os exemplos do mapeamento para o relacionamento 1:N dados no exemplo 2.
Responda: Para o exemplo 2.1 é possível construir um modelo lógico com uma única tabela (fusão das duas tabelas)? Sim/Não/Explique. Se sim, construa tabela e dê exemplos (com instâncias de entidades). Justifique sua resposta.
Para o exemplo 2.2, pede-se:
É possível fazer um modelo relacional com duas tabelas (e não 3, como no exemplo)? Sim/Não/Explique
Caso seja possível, construa o modelo relacional com duas tabelas. Exemplifique com valores (instâncias das entidades).
Apresente os diagramas ER e as tabelas do modelo relacional.
Você pode usar ferramentas online de modelagem ou (preferencialmente) o MysqlWorkbench.
Exercício 4 - Desafio
Opcional (para essa Unidade do Curso). Requer conhecimento do MysqWorkBench e das restrições das chaves primárias e estrangeiras.
Apesar da fase do modelo lógico não resultar na construção do Banco de Dados no SGBD, vamos nesse exercício nos antecipar ao estudo do modelo físico, fazendo uma implementação de um modelo lógico (que a rigor tem que ser convertido no modelo físico) no Mysql.
Para isso, vamos implementar o modelo lógico dado no Exemplo 2.2 acima, cujo diagrama no "padrão" do MysqlWorkBench é repetido abaixo na figura 23

Figura 23: Diagrama para Exercício 4
Para esse diagrama, pede-se:
Crie as tabelas do Banco no Mysql
Insira dados para as tabelas PESSOA e MOTO
Insira dados na tabela compra, representando instâncias da entidade PESSOAS comprando motos, que são instâncias da entidade MOTO.
Analise a inserção na tabela COMPRA em relação ao par de chaves nela presentes.
Entenda a(s) restrição(ções) criadas pela relação 1:N
Analise e responda: é possível, do ponto de vista de inserção coreta dos dados e manutenção das relações, usar para esse caso um relacionamento N:N? SIM/NÃO/Explique. Se sim, dê exemplos.
Referências
Artigo sobre mapeamento DER-Modelo Lógico: Mapeamento de Modelos ER para DDL da SQL
Mapeamento DER-Lógico Mapeamento de Modelos ER Modelo Lógico
Mapeamento DER-Modelo Lógico: ER-to-Relational Mapping
Mapeamento DER-Modelo Lógico: Mapeamento de Modelo ER-Lógico